

Business service
Server Installation & Support
Server setup, maintenance, upgrades, troubleshooting, and business continuity support for physical and virtual environments.
View serviceThis page converts our AI Mini Datacenter proposal into a web-ready format for business leaders evaluating a private GPU environment for model training, AI services, virtualization, and future compute expansion. It reflects the same infrastructure strategy prepared by 365 Admin Support and Services for enterprise-grade AI deployments.
The proposal is built around five high-performance GPU servers, 10Gb switching, multi-ISP BGP routing, defense-in-depth security, monitored power and cooling, and a phased roadmap that can grow into a larger AI platform over time.

GPU servers in the initial Phase 1 design
Core switching fabric for east-west compute traffic
IPv4 block planned for AI, VM, and network growth
Connectivity strategy with failover and routing control
Strategic objective
The objective of this engagement is to establish a compact but production-ready AI datacenter capable of running GPU-accelerated AI and machine learning workloads with enterprise-level reliability. Rather than relying only on rented cloud GPUs, the design gives the client direct control over compute capacity, data placement, security policy, and long-term infrastructure economics.
Rack, structured cabling, power distribution, and cooling preparation for a professional compute environment.
Five high-performance GPU servers mounted, configured, and prepared for enterprise AI workloads.
BGP router, 10Gb core switching, firewall, multi-ISP failover, and segmentation architecture.
Firewall policy, IPS/IDS, CCTV, access control, dashboards, alerting, and operational visibility.
On-site and remote backup strategy, documented DR planning, and recovery-readiness controls.
Hardware Foundation
The proposed deployment starts with a production-ready hardware foundation designed for enterprise AI compute rather than a generic office server room. Five GPU servers form the core compute layer, supported by enterprise networking, rack power planning, and operational resilience controls.
Rack form factor
Power redundancy goal
DDR5 ECC memory per node
NIC design for each server

AMD EPYC or Intel Xeon multi-core platform
128 GB to 256 GB DDR5 ECC registered memory
NVIDIA RTX 4090 or equivalent enterprise-class GPU
NVMe SSD for OS and scratch workloads plus enterprise HDD for bulk data
Dual-port 10Gb Ethernet for high-throughput infrastructure integration
This profile is meant to balance raw GPU throughput, storage performance, and reliability. NVMe reduces I/O bottlenecks during training workloads, ECC memory protects long-running jobs, and the platform leaves room for future GPU refresh cycles without redesigning the full environment.
Networking Architecture
The datacenter network is designed to avoid single points of failure while keeping GPU east-west traffic low-latency and internet-facing traffic controlled. The model uses a BGP-aware edge, enterprise firewalling, and 10Gb aggregation to keep compute, storage, and external connectivity aligned.
BGP router with multi-ISP connectivity and routing policy control
Firewall cluster or equivalent HA firewall posture for ingress and egress control
10Gb switching for compute, storage, and infrastructure aggregation
Segmented internal environment for GPU nodes, storage tiers, and management traffic
Primary high-bandwidth carrier for normal production traffic.
Active secondary provider for load balancing and immediate failover.
Tertiary provider used as a final continuity layer during broader outages.
Power, Cooling, and Storage

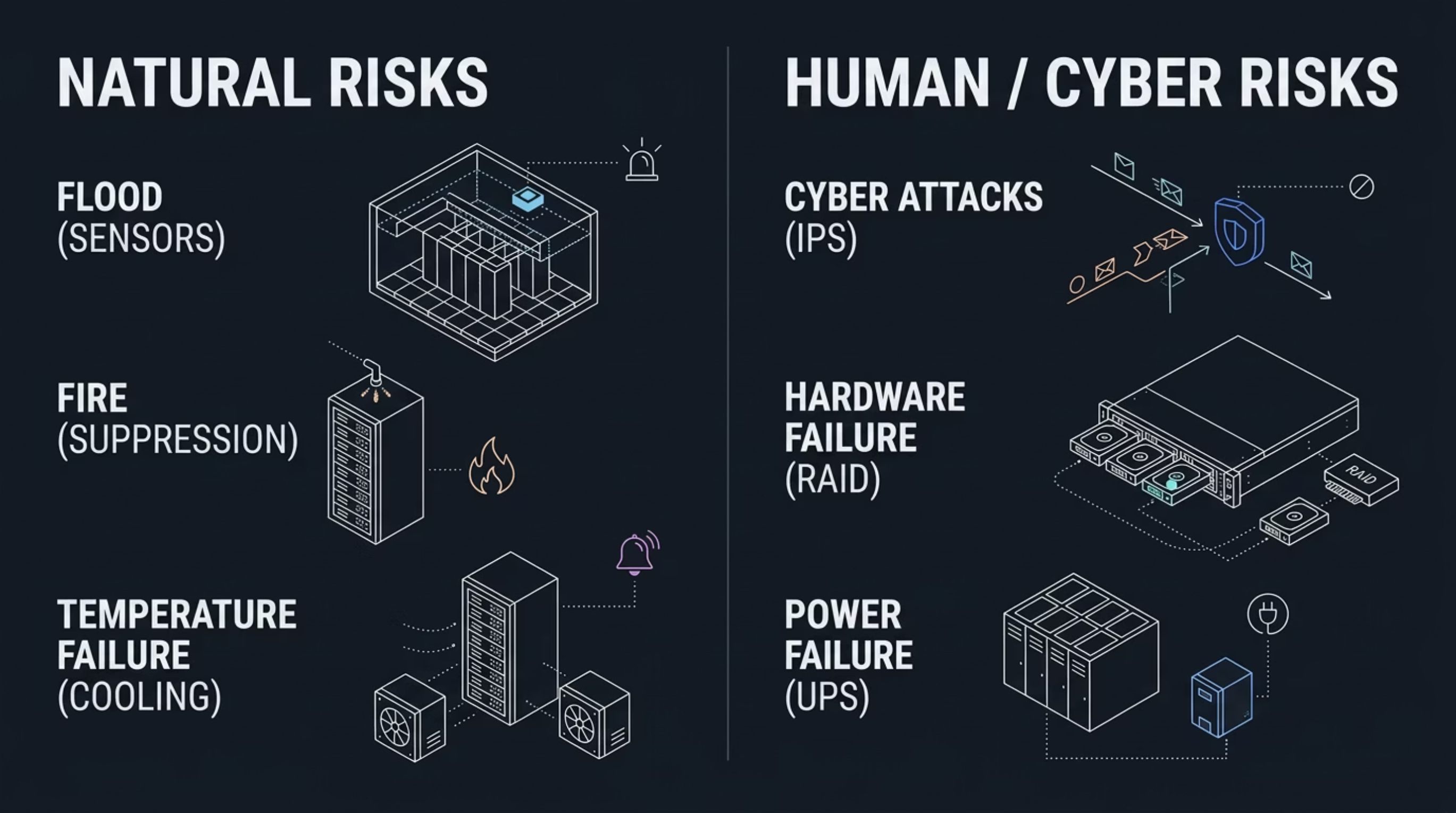
Security and Operations
A GPU datacenter hosting AI workloads, public services, and customer virtual machines is a high-value target. The proposal uses a defense-in-depth approach so that no single failure or compromise exposes the entire environment.
Sophos or equivalent next-generation firewall with inspection and application-layer policy enforcement.
Intrusion prevention with current signatures and anomaly detection for suspicious behavior.
VLANs and access policies isolating GPU compute, customer workloads, and management planes.
Whitelisted ports and protocols only, with deny-by-default discipline for exposed services.
The disaster recovery framework is intended to address both physical and cyber risks, including power disruption, cooling failure, hardware issues, flood, fire, and security events. Recovery planning becomes part of the infrastructure from the beginning rather than an afterthought.
Public IP planning and justification
The proposal justifies a /23 IPv4 block to support AI compute nodes, application services, customer VMs, network infrastructure, and future growth without repeated readdressing.
Compute node management, IPMI, and primary interfaces
Inference APIs, orchestration endpoints, and platform services
Tenant VM instances and hosted workloads
Routers, switches, firewalls, and management interfaces
Application delivery and security appliances
Reserved for Phase 2 and Phase 3 capacity growth
Scalability Roadmap
Five GPU servers, /23 IP plan, BGP routing, switching, security, and monitoring.
Additional GPU nodes added into the existing rack and network framework.
AI APIs, managed VM hosting, and GPU service offerings introduced.
Cloud burst integration through AWS, Azure, or Google Cloud for overflow capacity.
Project investment snapshot
The original proposal estimates that the dominant cost lies in the five GPU servers, while the remaining rack, networking, power, cooling, security, and monitoring stack is relatively efficient by comparison. It also frames the investment against recurring cloud GPU rental costs to show the long-term value of owned infrastructure.
| Component | Estimated Cost |
|---|---|
| GPU Servers (5 units) | Rs. 60,00,000 |
| Rack, PDU, and structured cabling | Rs. 1,10,000 |
| Core switch, firewall, and BGP router | Rs. 4,50,000 |
| UPS, battery extension, and power distribution | Rs. 3,20,000 |
| Cooling, CCTV, monitoring, and access control | Rs. 3,00,000 |
The deck compares this with cloud GPU rental, suggesting the owned environment can become economically compelling within roughly 24 to 30 months depending on sustained compute demand.
Next Steps
Proposal approval and investment confirmation
Physical site survey of the intended datacenter location
Vendor shortlist finalization and commercial validation
IRINN / NIXI IP application preparation
Project kickoff covering installation, testing, documentation, and handover
365 Admin Support and Services can adapt this structure for client site constraints, rack density, IP planning, procurement realities, and phased rollout budgets in Hyderabad and Telangana.
Proposal FAQ
Related Services
Server setup, maintenance, upgrades, troubleshooting, and business continuity support for physical and virtual environments.
View service
Structured cabling, LAN and WAN setup, rack dressing, patch panel work, Wi-Fi support, and network installation for modern business spaces.
View service
Business-focused cybersecurity support including endpoint protection, firewall management, vulnerability reviews, secure access, and practical risk reduction.
View service
Cloud planning, migration assistance, Microsoft cloud support, hosting guidance, and scalable infrastructure services for modern businesses.
View service
Backup planning, recovery readiness, restore support, and resilience measures for servers, endpoints, and business-critical data.
View service
Proactive day-to-day IT management for businesses that want dependable support, stable systems, and predictable technology operations.
View serviceFast business IT help
Talk to our team for managed IT services, networking, Microsoft 365 support, server assistance, or office IT expansion in Hyderabad.